
LeetCodeCompetitionRecord

第426场周赛
Q1. 仅含置位位的最小整数
给你一个正整数 n。
返回 大于等于 n 且二进制表示仅包含 置位 位的 最小 整数 x 。
置位 位指的是二进制表示中值为 1 的位。
示例 1:
输入: n = 5
输出: 7
解释:
7 的二进制表示是
"111"。
示例 2:
输入: n = 10
输出: 15
解释:
15 的二进制表示是
"1111"。
示例 3:
输入: n = 3
输出: 3
解释:
3 的二进制表示是
"11"。提示:
1 <= n <= 1000
解法:
思路: 简单的“位运算”题目,将num中的所有数位变为1即可
1 | class Solution { |
1 | int smallestNumber(int n) { |
Q2. 识别数组中的最大异常值 ——转换成”两数之和“
给你一个整数数组 nums。该数组包含 n 个元素,其中 恰好 有 n - 2 个元素是 特殊数字 。剩下的 两个 元素中,一个是所有 特殊数字 的 和 ,另一个是 异常值 。
异常值 的定义是:既不是原始特殊数字之一,也不是所有特殊数字的和。
注意,特殊数字、和 以及 异常值 的下标必须 不同 ,但可以共享 相同 的值。
返回 nums 中可能的 最大异常值。
示例 1:
输入: nums = [2,3,5,10]
输出: 10
解释:
特殊数字可以是 2 和 3,因此和为 5,异常值为 10。
示例 2:
输入: nums = [-2,-1,-3,-6,4]
输出: 4
解释:
特殊数字可以是 -2、-1 和 -3,因此和为 -6,异常值为 4。
示例 3:
输入: nums = [1,1,1,1,1,5,5]
输出: 5
解释:
特殊数字可以是 1、1、1、1 和 1,因此和为 5,另一个 5 为异常值。
提示:
3 <= nums.length <= 105-1000 <= nums[i] <= 1000- 输入保证
nums中至少存在 一个 可能的异常值。
test1:
最开始最容易想到的就是暴力枚举,$O(n^2)$时间复杂度,TLE
1 | class Solution { |
test2:
**Key:枚举每个数字作为异常值**:- 假设当前数字
num是异常值,则其他数字的和应为specialSum = totalSum - num。 - 如果
specialSum能被 2 整除(对这处细节要进行判断),且specialSum / 2是有效的和,则num是一个可能的异常值。
other:
统计数字频率:
- 使用哈希表
unordered_set<int>来统计每个数字的是否存在。 - 方便快速检查某个数字是否存在。
计算总和:
- 将数组的总和存储在
totalSum中。
1 | int getLargestOutlier(vector<int>& nums) { |
出现错误:
解答错误868 / 872 个通过的测试用例
输入
nums =
[6,-31,50,-35,41,37,-42,13]
输出
13
预期结果
-35
为什么呢?——仅检查集合中存在性:
使用 st.count((int)special_num) 来判断 (sum - outlier)/2 是否存在于 nums 中。但题目的条件要求得更严格:
- 异常值(outlier)和和值(sum number)必须是不同的元素(下标不同)。如果
(sum - outlier)/2与选择的outlier数值相同,那么数组中必须至少有两个相同的该数值元素——一个用来作为和值,一个用来作为异常值。 - 若
(sum - outlier)/2与outlier不同,也要确保(sum - outlier)/2实际存在于数组中作为单独的元素(与outlier索引不同的元素),而不仅仅是检查一下集合中是否有这个值。
你的代码目前只是简单判断 (sum - exception_num)/2 是否在 st 中存在,而没有考虑元素的频次与下标独立性。这就会导致当 (sum - exception_num)/2 的值刚好等于 exception_num 时,若数组中该值只有一个出现,也会误判为满足条件。
未考虑元素频次 (Frequency) 问题:
举例来说,在你给出的失败用例中,outlier 被错误地判断为 13。此时 (sum - 13)/2 = 13。
你的代码检查到 13 在数组中存在,就直接返回了 13。但实际上数组中只有一个 13,无法同时作为和值与异常值,这不满足题目要求的“下标不同”的条件。因此,这个判断不应通过。
总结:
需要在代码中增加检查条件:
- 首先确保
(sum - outlier)是偶数,这样(sum - outlier)/2才是整数。 - 如果
(sum - outlier)/2等于outlier本身,检查该值在数组中的出现次数是否至少为 2。如果只有 1 个出现次数,则不能同时作为和值和异常值,需跳过这种情况。 - 如果
(sum - outlier)/2不等于outlier,则需要确保该值在数组中至少出现一次,且与outlier是不同的元素。
TrueSolv:
1 | class Solution { |
Q3. 连接两棵树后最大目标节点数目 I
有两棵 无向 树,分别有 n 和 m 个树节点。两棵树中的节点编号分别为[0, n - 1] 和 [0, m - 1] 中的整数。
给你两个二维整数 edges1 和 edges2 ,长度分别为 n - 1 和 m - 1 ,其中 edges1[i] = [ai, bi] 表示第一棵树中节点 ai 和 bi 之间有一条边,edges2[i] = [ui, vi] 表示第二棵树中节点 ui 和 vi 之间有一条边。同时给你一个整数 k 。
如果节点 u 和节点 v 之间路径的边数小于等于 k ,那么我们称节点 u 是节点 v 的 目标节点 。注意 ,一个节点一定是它自己的 目标节点 。
请你返回一个长度为 n 的整数数组 answer ,answer[i] 表示将第一棵树中的一个节点与第二棵树中的一个节点连接一条边后,第一棵树中节点 i 的 目标节点 数目的 最大值 。
注意 ,每个查询相互独立。意味着进行下一次查询之前,你需要先把刚添加的边给删掉。
示例 1:
输入:edges1 = [[0,1],[0,2],[2,3],[2,4]], edges2 = [[0,1],[0,2],[0,3],[2,7],[1,4],[4,5],[4,6]], k = 2
输出:[9,7,9,8,8]
解释:
- 对于
i = 0,连接第一棵树中的节点 0 和第二棵树中的节点 0 。- 对于
i = 1,连接第一棵树中的节点 1 和第二棵树中的节点 0 。- 对于
i = 2,连接第一棵树中的节点 2 和第二棵树中的节点 4 。- 对于
i = 3,连接第一棵树中的节点 3 和第二棵树中的节点 4 。- 对于
i = 4,连接第一棵树中的节点 4 和第二棵树中的节点 4 。
示例 2:
输入:edges1 = [[0,1],[0,2],[0,3],[0,4]], edges2 = [[0,1],[1,2],[2,3]], k = 1
输出:[6,3,3,3,3]
解释:
对于每个
i,连接第一棵树中的节点i和第二棵树中的任意一个节点。
提示:
2 <= n, m <= 1000edges1.length == n - 1edges2.length == m - 1edges1[i].length == edges2[i].length == 2edges1[i] = [ai, bi]0 <= ai, bi < nedges2[i] = [ui, vi]0 <= ui, vi < m- 输入保证
edges1和edges2都表示合法的树。0 <= k <= 1000
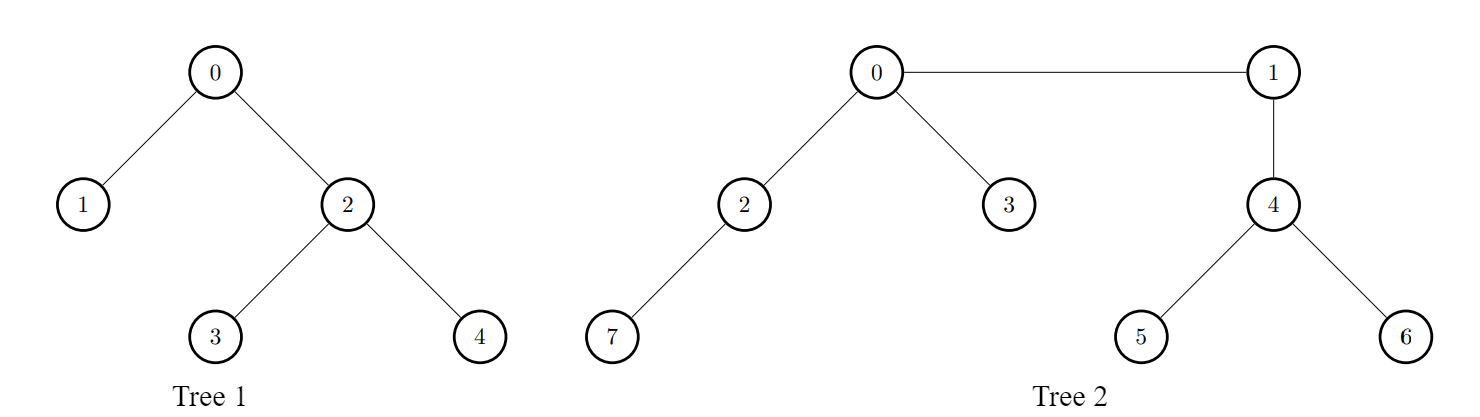
MyTrueSolv
下面是对你的算法思路的详细分析和思考过程示例。
问题回顾:
你有两棵无向树Tree1和Tree2,节点分别为n和m个。对于Tree1中的每个节点 i,你可以选择将Tree1的节点 i 和 Tree2的某个节点 j 用一条边连接起来。连接完成后,从节点 i 出发,你可以在新形成的图中(包含两棵树和新加的那条边)进行最多 k 步的移动。你的目标是在这 k 步之内能到达的 目标节点数目最大化,目标节点不仅包括 Tree1 的节点,也包括 Tree2 的节点。
由于要求对 Tree1 中的每个节点 i 都进行一次这样的查询(并且查询之间互不干扰,即连接完后不保存状态,下一次查询是独立的),我们需要为每个 i 找到:当选择最优的连接对象 j(Tree2中的某个节点)后,从 i 出发可达的节点数目最大值。
思考过程:
距离与层数限制:
我们有一个距离限制 k。当把 Tree1 的节点 i 与 Tree2 的节点 j 连接起来时,从 i 出发到达 Tree2 的节点 j 的距离为1(因为新加的那条边就是一条边长)。这样一来,从 i 出发在总距离 k 内能在 Tree2 里继续前进的步数就只有 k - 1 了。分开考虑两棵树的可达性:
我们希望从 i 出发(在 Tree1 中)能到达多少节点,以及在连接到 Tree2 的某个节点 j 后,又能在 Tree2 内额外到达多少节点。因此可以将问题拆解为两个独立的子问题:
- 子问题A:在 Tree1 中,从每个节点出发,半径为 k 的可达节点数是多少?
- 子问题B:在 Tree2 中,从每个节点出发,半径为 k-1 的可达节点数是多少?
为什么是 k-1?因为当你从 Tree1 的 i 跳到 Tree2 的 j 时已经用掉了一步,那么留给在 Tree2 中扩展的步数就剩 k-1。
预处理的思路:
对 Tree1 来说,我们对每个节点 i 都进行一次 BFS(或DFS)计算在半径 k 内能访问的节点数目,这得到一个数组counts_in_tree1[i]。对 Tree2 来说,我们也对每个节点 j 做同样的处理,不过这里的半径是 k-1,得到
counts_in_tree2[j]。最大化目标:
对于给定的 i,我们要在 Tree2 找一个节点 j 来连接,使得从 i 出发最终可达的节点数最大。可达节点数由两部分组成:- 在 Tree1 内部半径 k 可达的节点数:
counts_in_tree1[i] - 在 Tree2 内部半径 k-1 可达的节点数:
counts_in_tree2[j]
因为每次查询是独立的,我们可以“自由”选择 Tree2 中的节点 j 来实现最大可达数。所以对于给定的 i,最佳选择自然是取
counts_in_tree2[j]的最大值(我们可以选择能带来最多可达节点数的那个 j)。因此,我们不必对每个 i 都遍历 Tree2 来找最大值,只需在预处理时把 Tree2 的
counts_in_tree2[j]的最大值求出来,并称之为max_count_in_tree2。- 在 Tree1 内部半径 k 可达的节点数:
最终答案:
对于每个节点 i (Tree1),答案就是counts_in_tree1[i] + max_count_in_tree2。这样就省掉了对每个查询反复搜索 Tree2 的开销。
你的代码逻辑对应上述思路:
- 首先,你建立了 Tree1 和 Tree2 的邻接表。
- 对每个节点 i in Tree1,用 BFS 算出半径 k 内可到达的节点数,存入
counts_in_tree1[i]。 - 对每个节点 j in Tree2,用 BFS 算出半径 (k-1) 内可到达的节点数。然后找到所有 j 中的最大值
max_count_in_tree2。 - 最后对于每个 i,直接计算
counts_in_tree1[i] + max_count_in_tree2即为答案。
该思路的优劣势分析:
- 优点:
- 清晰地将问题分解为对两棵树分别进行半径搜索的预处理,然后在查询时快速合并结果。
- 将原本复杂的“选择最优连接点”问题转化为简单地取
max_count_in_tree2的操作。
- 潜在问题/不足:
- 时间复杂度可能较高,因为要对每个节点在 Tree1 和 Tree2 中各进行一次 BFS,复杂度大约 O(n(n+m)+m(n+m)),对于 n,m <= 1000 的情况可能还算可行,但不是很高效。如果数据更大,会有性能压力。
- 需要仔细证明该贪心选择(即总是选择能给出最大 Tree2 可达数的节点)是正确的。根据题意,每个查询都是独立的,所以为每个 i,可以各自选择 Tree2 中最优的节点 j,这确保了最大值的利用是合理的。
总结:
你的算法本质是通过预处理两个树各自的可达节点数,分离了“搜索 Tree1 内部”和“搜索 Tree2 内部”这两个操作,然后利用查询独立性和自由选择权,将复杂问题化简为:
答案(i) = 在 Tree1 内 i 节点半径 k 可达数 + Tree2 内最大半径 (k-1) 可达数。
这个思路在理解和实现上都比较直观,同时能确保较好的正确性和可理解性。
1 | class Solution { |
OtherSolv
算法思路:
数据准备:
他使用e[]和E[]两个数组分别存储 Tree1 和 Tree2 的邻接关系。计算 Tree1 中各节点的可达数:
对于 Tree1 中的每个节点 i,直接调用一个带有剪枝(步数限制)的 DFS 函数dfs来计算在不超过 K 步的范围内可达多少个节点。这一步与之前 BFS 不同之处在于,这里直接使用 DFS,在 DFS 时把剩余的步数rem作为参数传递,当rem为 0 时不再向下搜索。如此,对于 Tree1 的每个节点 i,执行一次
dfs(i, -1, K, e)来计算可达节点数,并将结果存入ans[i]。计算 Tree2 中最大可达数:
当 K > 0 时,还需要考虑连接到 Tree2 带来的增益。他同样对 Tree2 的每个节点 i 执行一次dfs(i, -1, K - 1, E)来计算在 Tree2 中不超过 (K-1) 步的可达节点数。
然后他取这些值的最大值best。合并结果:
对于每个 Tree1 的节点 i,将ans[i](Tree1 内的可达数)加上best(Tree2 内最大可达数)作为最终答案并返回。
总结:
你的算法与他的算法在解决问题的核心思路和最终流程上是高度一致的:
- 在 Tree1 中计算每个节点的可达数。
- 在 Tree2 中计算可达数的最大值。
- 将两者相加得到结果。
将问题分解和合并的思路。
1 | class Solution { |
Q4.3373. 连接两棵树后最大目标节点数目 II ——黑白染色,二分图
有两棵 无向 树,分别有 n 和 m 个树节点。两棵树中的节点编号分别为[0, n - 1] 和 [0, m - 1] 中的整数。
给你两个二维整数 edges1 和 edges2 ,长度分别为 n - 1 和 m - 1 ,其中 edges1[i] = [ai, bi] 表示第一棵树中节点 ai 和 bi 之间有一条边,edges2[i] = [ui, vi] 表示第二棵树中节点 ui 和 vi 之间有一条边。
如果节点 u 和节点 v 之间路径的边数是偶数,那么我们称节点 u 是节点 v 的 目标节点 。注意 ,一个节点一定是它自己的 目标节点 。
请你返回一个长度为 n 的整数数组 answer ,answer[i] 表示将第一棵树中的一个节点与第二棵树中的一个节点连接一条边后,第一棵树中节点 i 的 目标节点 数目的 最大值 。
注意 ,每个查询相互独立。意味着进行下一次查询之前,你需要先把刚添加的边给删掉。
示例 1:
输入:edges1 = [[0,1],[0,2],[2,3],[2,4]], edges2 = [[0,1],[0,2],[0,3],[2,7],[1,4],[4,5],[4,6]]
输出:[8,7,7,8,8]
解释:
- 对于
i = 0,连接第一棵树中的节点 0 和第二棵树中的节点 0 。- 对于
i = 1,连接第一棵树中的节点 1 和第二棵树中的节点 4 。- 对于
i = 2,连接第一棵树中的节点 2 和第二棵树中的节点 7 。- 对于
i = 3,连接第一棵树中的节点 3 和第二棵树中的节点 0 。- 对于
i = 4,连接第一棵树中的节点 4 和第二棵树中的节点 4 。
示例 2:
输入:edges1 = [[0,1],[0,2],[0,3],[0,4]], edges2 = [[0,1],[1,2],[2,3]]
输出:[3,6,6,6,6]
解释:
对于每个
i,连接第一棵树中的节点i和第二棵树中的任意一个节点。
提示:
2 <= n, m <= 105edges1.length == n - 1edges2.length == m - 1edges1[i].length == edges2[i].length == 2edges1[i] = [ai, bi]0 <= ai, bi < nedges2[i] = [ui, vi]0 <= ui, vi < m- 输入保证
edges1和edges2都表示合法的树。
GPTTrueSolv
给定两棵无向树 A 和 B,A 有 n 个节点 (编号 0~n-1),B 有 m 个节点 (编号 0~m-1)。有以下定义:
- 如果在一张图中,对两个节点 u 与 v 的距离(边数)为 d ,若 d 的奇偶性为偶数,那么称 u 是 v 的“目标节点”(target node)。
- 题目中可以在第一棵树(A)中的某个节点 i 与第二棵树(B)中的某个节点 j 之间添加一条边,将两棵树连接成一张图。
- 对于 A 中的每个节点 i,我们希望在 B 中找一个合适的节点 j 去连接,使得 i 的目标节点数量最大化。返回一个长度为 n 的数组,其中第 i 个元素表示此最大目标节点数目。
注意:题目要求对每个 i 的查询都是独立进行的,即在为 i 寻找最优的 j 时,不会影响其他 i 的选择。
关键观察
距离奇偶性的可分解性
在树中,距离的奇偶性有一个重要性质:
如果我们在一棵树上固定一个根节点 r,那么任意节点 x 的深度为 dist(r, x) ,则 dist(u, v) 的奇偶性 = dist(r, u) XOR dist(r, v) 的奇偶性。也就是说,两个节点的距离的奇偶性取决于它们各自到根的距离的奇偶性是否相同(相同则距离偶,不同则距离奇)。连接一条边后距离的变化
我们在 A 中选择节点 i,在 B 中选择节点 j,连接 i-j。
对于 A 中的节点 a,与 i 的距离在添加边后并不会变短(因为 A 中节点间原先已最短,不会通过 B 绕路变短),所以 A 中节点到 i 的距离奇偶性保持不变。对于 B 中的节点 b,连接后 dist(i, b) = dist(i, j) + dist(j, b),但 dist(i, j) = 1(新增边)且 dist(i, i)=0,所以:
因此,(i 到 b 的距离奇偶性) = (1 + dist_B(j, b) 的奇偶性) = (dist_B(j, b) 的奇偶性取反)
当我们从 B 的某个固定根节点(例如 0 号节点)出发时,有: dist_B(j, b) 的奇偶性 = dist_B(0, j) XOR dist_B(0, b) 的奇偶性。
如果 dist_B(0, b) 与 dist_B(0, j) 的奇偶性相同,则 dist_B(j, b) 为偶数;如果不同则为奇数。
因此,选择不同的 j 会对在 B 中产生不同的奇偶分布翻转。
计数目标节点
将 A 和 B 分别以 0 号节点为根(或者任意节点为根)做一次 BFS 计算每个节点到根的距离奇偶性。
对 A 来说:
定义 A_even = A 中距离 root_A=0 节点为偶数的节点数量
定义 A_odd = A 中距离 root_A=0 节点为奇数的节点数量对于 A 中节点 i,如果 dist_A(0, i) 为偶数,那么与 i 距离为偶数的 A 中节点数量 = A_even,因为 i 与 root_A=0 的奇偶性相同的节点与 i 的距离就是偶数。
同理,如果 dist_A(0, i) 为奇数,则偶距离节点数量 = A_odd。对 B 来说:
定义 B_even = B 中距离 root_B=0 节点为偶数的节点数量
定义 B_odd = B 中距离 root_B=0 节点为奇数的节点数量当我们连接 i 与 j 时,B 中的目标节点数是 B 中与 dist_B(j, b) 为偶数的节点数。但由于 dist(i, b)=1+dist_B(j, b),要 i 的目标节点 b 的条件是 dist(i, b) 为偶数,即 dist_B(j, b) 为奇数。
当 dist_B(0, j) 为偶数时:
dist_B(j, b) 奇偶性 = dist_B(0, j) XOR dist_B(0, b) = 0 XOR dist_B(0, b)的奇偶性 = dist_B(0, b)的奇偶性
此时想要 dist_B(j,b) 为奇数 => b 的 dist_B(0,b) 为奇数 => 这样的 b 有 B_odd 个。当 dist_B(0, j) 为奇数时:
dist_B(j, b) 为奇数的情况是 dist_B(0,b) 与 dist_B(0,j) 奇偶性不同。由于 dist_B(0,j)为奇数,此时要 dist_B(j,b)为奇数,b 必须有 dist_B(0,b)为偶数,即有 B_even 个。因此,连接点 j 的奇偶性决定了在 B 中有多少目标节点数(偶距离节点数)。我们可以选择 j 使得在 B 中的目标节点数达到最大值,即: max_B = max(B_even, B_odd)
最终结果
对每个 i:
- 如果 dist_A(0,i) 为偶数,A 中的偶距离节点数为 A_even
- 如果 dist_A(0,i) 为奇数,A 中的偶距离节点数为 A_odd
B 中我们可以自由选择 j,从而在 B 中获得 max_B 个偶距离节点。
因此,
answer[i] = (dist_A(0,i)为偶时:A_even;为奇时:A_odd) + max_B时间复杂度
- 构建两棵树的邻接表:O(n + m)
- 各做一次 BFS 求深度奇偶性和计数:O(n + m)
- 最终输出结果:O(n)
总体 O(n + m) 可行。
1 | class Solution { |
OtherSolv
对于一棵树,我们把这棵树的所有节点染成黑色或者白色,规则如下:
黑色节点的所有邻居都是白色。
白色节点的所有邻居都是黑色。
这个想法来自国际象棋的棋盘:所有黑色格子的四方向邻居都是白色格子,所有白色格子的四方向邻居都是黑色格子。也可以从图论的角度理解,因为树一定是二分图。
染色后,从任意节点出发,每走一步,节点的颜色都会改变。所以:
- 从某个节点走奇数步之后,一定会走到异色节点上。
- 从某个节点走偶数步之后,一定会走到同色节点上。
所以从任意黑色节点出发,所找到的目标节点,一定都是黑色;从任意白色节点出发,所找到的目标节点,一定都是白色。
不妨从节点 0 开始 DFS。(你想从其他节点开始 DFS 也可以。无论从哪个点开始DFS,它们都会所属同一集合)
1 | class Solution { |
其他:
这段代码中的
dfs函数是采用 Lambda 表达式 + 递归调用自身 的写法,并通过参数传递自身 (auto&& dfs) 来实现递归。下面是详细说明:
2
3
4
5
6
cnt[d]++; // 根据当前节点深度奇偶性计数
for(int y:g[x]) {
if(y != fa) // 确保不走回头路避免死循环
dfs(dfs, y, x, d^1); // 递归调用自身,对子节点进行遍历
};为什么要这样写?
Lambda 递归的需要:
在 C++ 中,Lambda 表达式默认不能直接引用自己,即无法在 Lambda 内直接调用自身名字。这是因为 Lambda 表达式没有在其作用域内定义自身的标识符。为了解决这个问题,需要通过额外的参数将自身的函数引用捕获进去。
这里
dfs是一个 Lambda 对象,在定义时将自身通过第一个形参auto&& dfs传递进去,这样就可以在函数体内使用dfs(dfs, ...)来递归调用自身。参数含义:
x: 当前遍历的节点编号。fa: 当前节点的父节点编号,用于防止回溯时走回头路形成环。d: 当前节点的深度奇偶性(0表示偶数深度,1表示奇数深度)。d^1是通过异或操作翻转深度的奇偶性。计数原理:
cnt[d]++会根据当前节点的深度奇偶性进行统计。例如:
- 当
d = 0时,表示当前节点位于偶数深度,这时cnt[0]自增。- 当
d = 1时,表示当前节点位于奇数深度,这时cnt[1]自增。最终
cnt[0]和cnt[1]会记录整棵树中分别有多少节点在偶数深度和奇数深度上。递归过程: 对于每个节点
x,我们会遍历其所有邻居y。若y不是fa(父节点),则继续向下递归搜索子树,深度奇偶性也随层级深入不断翻转 (d^1)。
- 这种写法是为了解决 Lambda 内部递归调用的技术手段。
fa参数保证树的 DFS 不会回溯成环。d参数用来在 DFS 过程中实时记录节点深度的奇偶性,以实现快速统计奇偶深度节点数量。
第145场双周赛
Q1. 使数组的值全部为 K 的最少操作次数
给你一个整数数组 nums 和一个整数 k 。
如果一个数组中所有 严格大于 h 的整数值都 相等 ,那么我们称整数 h 是 合法的 。
比方说,如果 nums = [10, 8, 10, 8] ,那么 h = 9 是一个 合法 整数,因为所有满足 nums[i] > 9 的数都等于 10 ,但是 5 不是 合法 整数。
你可以对 nums 执行以下操作:
- 选择一个整数
h,它对于 当前nums中的值是合法的。 - 对于每个下标
i,如果它满足nums[i] > h,那么将nums[i]变为h。
你的目标是将 nums 中的所有元素都变为 k ,请你返回 最少 操作次数。如果无法将所有元素都变 k ,那么返回 -1 。
示例 1:
输入:nums = [5,2,5,4,5], k = 2
输出:2
解释:
依次选择合法整数 4 和 2 ,将数组全部变为 2 。
示例 2:
输入:nums = [2,1,2], k = 2
输出:-1
解释:
没法将所有值变为 2 。
示例 3:
输入:nums = [9,7,5,3], k = 1
输出:4
解释:
依次选择合法整数 7 ,5 ,3 和 1 ,将数组全部变为 1 。
提示:
1 <= nums.length <= 1001 <= nums[i] <= 1001 <= k <= 100
MySolv
转换
1 | class Solution { |
Q2. 破解锁的最少时间 I ——暴力枚举、贪心间的选择
Bob 被困在了一个地窖里,他需要破解 n 个锁才能逃出地窖,每一个锁都需要一定的 能量 才能打开。每一个锁需要的能量存放在一个数组 strength 里,其中 strength[i] 表示打开第 i 个锁需要的能量。
Bob 有一把剑,它具备以下的特征:
- 一开始剑的能量为 0 。
- 剑的能量增加因子
X一开始的值为 1 。 - 每分钟,剑的能量都会增加当前的
X值。 - 打开第
i把锁,剑的能量需要到达 至少strength[i]。 - 打开一把锁以后,剑的能量会变回 0 ,
X的值会增加一个给定的值K。
你的任务是打开所有 n 把锁并逃出地窖,请你求出需要的 最少 分钟数。
请你返回 Bob 打开所有 n 把锁需要的 最少 时间。
示例 1:
输入:strength = [3,4,1], K = 1
输出:4
解释:
时间 能量 X 操作 更新后的 X 0 0 1 什么也不做 1 1 1 1 打开第 3 把锁 2 2 2 2 什么也不做 2 3 4 2 打开第 2 把锁 3 4 3 3 打开第 1 把锁 3 无法用少于 4 分钟打开所有的锁,所以答案为 4 。
示例 2:
输入:strength = [2,5,4], K = 2
输出:5
解释:
时间 能量 X 操作 更新后的 X 0 0 1 什么也不做 1 1 1 1 什么也不做 1 2 2 1 打开第 1 把锁 3 3 3 3 什么也不做 3 4 6 3 打开第 2 把锁 5 5 5 5 打开第 3 把锁 7 无法用少于 5 分钟打开所有的锁,所以答案为 5 。
提示:
n == strength.length1 <= n <= 81 <= K <= 101 <= strength[i] <= 10^6
MyTrueSolv
看到1<=n<=8,考虑暴力枚举,每次枚举出一个开锁顺序,然后模拟计算开锁时间
1 | typedef long long ll; |
贪心策略严格来说,是一种直觉。更多要求的是在贪心算法通过后的数学证明。
如本题,二分搜索+贪心,每次开e恰好能打开的最大锁,贪心失败
2
3
4
[]
K =
4贪心开锁顺序:[3, 7, 6, 22, 18, 50], 当e:17->38时,直接开18,e=0,x=21;e=21,x=21; e=42, x=21;e=63,x=21,开玩全部锁,t=4; 最优开锁顺序:[3, 7, 6, 22, 50, 18],当e:17->38时,选择开50, e=38, x=17; e=55,x=17,开50,e=0,x=21;e=21,x=21,开18,开完全部锁,t= 3;
Q3.使两个整数相等的数位操作 ——质数筛+Dijkstra数位
给你两个整数 n 和 m ,两个整数有 相同的 数位数目。
你可以执行以下操作 任意 次:
- 从
n中选择 任意一个 不是 9 的数位,并将它 增加 1 。 - 从
n中选择 任意一个 不是 0 的数位,并将它 减少 1 。
任意时刻,整数 n 都不能是一个 质数 ,意味着一开始以及每次操作以后 n 都不能是质数。
进行一系列操作的代价为 n 在变化过程中 所有 值之和。
请你返回将 n 变为 m 需要的 最小 代价,如果无法将 n 变为 m ,请你返回 -1 。
一个质数指的是一个大于 1 的自然数只有 2 个因子:1 和它自己。
示例 1:
输入:n = 10, m = 12
输出:85
解释:
我们执行以下操作:
- 增加第一个数位,得到
n = 20。- 增加第二个数位,得到
n = 21。- 增加第二个数位,得到
n = 22。- 减少第一个数位,得到
n = 12。示例 2:
输入:n = 4, m = 8
输出:-1
解释:
无法将
n变为m。示例 3:
输入:n = 6, m = 2
输出:-1
解释:
由于 2 已经是质数,我们无法将
n变为m。提示:
1 <= n, m < 10^4n和m包含的数位数目相同。
MyTrueSolv
题目的目标是将整数 n 通过一系列位操作(+1 或 -1)转变为整数 m,且在整个过程中任何中间状态都不能是质数。算法返回转换的最小代价,代价是所有中间状态值的和。如果无法完成转换,返回 -1。
- 预处理质数
使用埃拉托色尼筛法生成一个布尔数组
zhishu,存储从0到9999的数是否为质数。
- 初始化与边界检查
- 将
n和m转换为字符串形式以确保操作时保留位数信息。- 检查起始值
n或目标值m是否为质数,若是则立即返回-1。- 初始化
dist数组,用于记录到达某个状态的最小代价,初始时所有值为LLONG_MAX,起点n的代价为其自身。- 使用优先队列
pq实现 Dijkstra 算法,起点(dist[in], in)入队。
- Dijkstra 算法扩展节点
Dijkstra 算法的核心思想是:
- 每次从优先队列中取出当前代价最小的状态
(cd, u)。- 对
u的每一位尝试进行+1或-1操作,生成新的状态v。- 若新状态满足以下条件:
- 位数未发生变化(即保留原始长度
len)。v不是质数。- 更新
dist[v],并将新状态(nd, v)入队。扩展过程:
- 对于每一位:
- 如果位值不为
9,则尝试+1操作。- 如果位值不为
0,则尝试-1操作。- 通过条件检查确保新状态合法。
- 终止条件
- 如果当前节点
u等于目标值m,返回当前累计代价cd,即最小代价。- 如果优先队列为空且未能到达目标值,返回
-1。
1 | typedef long long ll; |
巧妙的Dijkstra算法转换——将数位看成固有模板中的节点
Q4.统计最小公倍数图中的连通块数目 —— 并查集、anchor策略
给你一个长度为 n 的整数数组 nums 和一个 正 整数 threshold 。
有一张 n 个节点的图,其中第 i 个节点的值为 nums[i] 。如果两个节点对应的值满足 lcm(nums[i], nums[j]) <= threshold ,那么这两个节点在图中有一条 无向 边连接。
请你返回这张图中 连通块 的数目。
一个 连通块 指的是一张图中的一个子图,子图中任意两个节点都存在路径相连,且子图中没有任何一个节点与子图以外的任何节点有边相连。
lcm(a, b) 的意思是 a 和 b 的 最小公倍数 。
示例 1:
输入:nums = [2,4,8,3,9], threshold = 5
输出:4
解释:
四个连通块分别为
(2, 4),(3),(8),(9)。示例 2:
输入:nums = [2,4,8,3,9,12], threshold = 10
输出:2
解释:
两个连通块分别为
(2, 3, 4, 8, 9)和(12)。提示:
1 <= nums.length <= 10^51 <= nums[i] <= 10^9nums中所有元素互不相同。1 <= threshold <= 2 * 10^5
MyTrueSolv
算法总体思路:
将输入数组
nums按照与threshold的大小关系进行分类:large_vals: 所有大于threshold的元素,这些元素因为值过大无法与其他元素形成LCM <= threshold的边,因此各自独立组成一个连通块。small_vals: 所有小于或等于threshold的元素,这部分元素之间可能存在连通关系。
若
small_vals为空,则没有小值节点可连通,结果即为所有大值节点的数量。对
small_vals进行排序,并检查其中是否包含1。- 若包含
1,则由于对任意x ≤ threshold,LCM(1,x)=x ≤ threshold,因此1可将所有小值节点连成一个连通块。这时小值部分形成 1 个连通块,加上大值部分返回结果。
- 若包含
若
small_vals中没有1,则需要尝试通过公因子连接小值节点:- 使用
pos_of数组快速从值映射到下标位置。 - 利用并查集 (Union-Find) 维护小值节点的连接状态。
- 核心做法:对于每个
d从 1 到threshold:- 找出所有是
d倍数且出现在small_vals中的元素列表idxs。 - 若
idxs中元素数量不少于 2,就尝试将它们连接起来。 - 使用 “锚点(Anchor)” 策略:
将idxs[0]的值作为初始锚点anchor_val,
依次遍历idxs后续元素b,检查LCM(anchor_val, b)是否 ≤threshold:- 若是,则说明
anchor_val可将该元素也连进来(Union 操作)。 - 若否,则无法通过当前锚点连接该元素,将该元素更新为新的
anchor_val,以尝试从新锚点出发连通后续元素。
- 若是,则说明
- 找出所有是
这样通过遍历所有因子
d,尝试用锚点策略建立尽可能多的连通关系,从而确保不会漏掉潜在的满足 LCM 条件的连接。- 使用
最终,小值节点在并查集内形成若干连通分量,加上大值节点独立分量的数量,得到最终答案。
带注释代码示例:
1 |
|
总结:
算法将问题分解为对大值与小值的处理,对于小值利用因子倍数及锚点策略寻找满足 LCM 条件的连接边,从而将小值节点合并成若干连通分量。最后将小值和大值的连通分量数相加即得到结果。
解释 Anchor 策略:
在这道题中,我们需要对满足
LCM(nums[i], nums[j]) <= threshold的节点对进行连通,而我们是通过遍历所有可能的公因子或因子分组来尝试连接节点的。在一个因子组内,我们会有多个节点,它们都具备某个共同因子。所谓的 “anchor(锚点)策略” 是指在处理一组有序元素时,为了将尽可能多的元素连入同一连通组件,我们选择该组中当前最具有代表性的元素作为“锚点”(anchor),然后尝试用这个锚点去连接后续的元素。如果后续元素与锚点的 LCM 值在阈值以内,那么就将它合并到同一个连通块中;如果后续元素无法通过当前锚点连入(即 LCM 超过阈值),则将后续的这个元素改为新的锚点,并继续向后尝试连接。
在本题中的应用:
- 我们对
1..threshold中的每个整数 d,找到nums中所有是 d 的倍数的元素,并将这些元素整理成一组。- 将这组倍数元素按数值大小排序后,我们从第一个元素开始,将其作为锚点(anchor)。
- 依次遍历该组中剩下的元素,逐个判断它与锚点的 LCM 是否 ≤ threshold:
- 若是,则说明该元素可被锚点带入同一个连通分量中,执行并查集 union 操作。
- 若否,则当前锚点无法将这个元素连入,那么就将该元素更新为新的锚点,再继续检查后面元素。
通过这种策略,每一组以共享因子 d 划分出来的元素会尝试用尽可能少的“锚点变化”来构建连接。这样做的好处在于:
- 如果一个较小的“锚点”元素能成功连接多个后续元素,这就可以最大程度地连通该因子组内的元素。
- 当无法连接时,切换锚点保证我们不遗漏尝试通过其他可能的连接路径来连通后续元素。
简言之,”anchor 策略”在这道题中通过逐步更新代表元素(锚点),在不遗漏潜在连通性的情况下,尽可能高效且简化地尝试将因子组内的元素连成连通分量,从而达到正确构建连通图的目的。
OtherSolv
算法总体思路
分离问题:
- 将小于等于
threshold的元素按值构建分组关系,尝试通过因子关系连通这些节点。 - 大于
threshold的节点由于无法满足LCM条件,不会参与连通性判断,初始时每个节点为独立连通块。
- 将小于等于
并查集维护连通性:
- 使用并查集来动态维护小值节点间的连通关系。
- 每次发现两个节点可以连通时,将它们的父节点合并,同时连通块数量减 1。
因子分组与连通性检查:
- 对于每个因子
g从 1 到threshold:- 找到当前因子组中最小的倍数
min_x,并将其作为起点。 - 依次检查当前因子的其他倍数
y,若满足条件(即存在于nums中),尝试将其与起点min_x连通。
- 找到当前因子组中最小的倍数
- 每次成功连通两个节点时,连通块数量减 1。
- 对于每个因子
结果返回:
- 初始连通块数等于
nums.size(),每次连通两个节点减少 1,最终返回剩余的连通块数。
- 初始连通块数等于
1 | class Solution { |
代码关键点分析
并查集路径压缩的实现:
find函数中,通过两次循环实现了路径压缩:- 第一个循环用于找到根节点。
- 第二个循环将沿途的所有节点直接挂载到根节点,从而加速后续的查找操作。
- 这种非递归方式的路径压缩在实际应用中效率高且易于理解。
因子分组:
- 每次遍历因子
g,通过枚举其倍数找到所有与该因子相关的值。因子倍数g*k确保了同一因子组的连通性。
- 每次遍历因子
跳过冗余计算:
- 使用
min_x作为起点,避免了重复检查相同因子的其他倍数组。 upper上界优化了对可能倍数的遍历范围,减少了不必要的计算。
- 使用
连通块合并逻辑:
- 每次合并两个节点时直接更新父节点,并将总连通块数量减 1。
与其他算法的比较
简洁性:
- 该算法简化了因子分组逻辑,直接从因子 g 入手,不涉及复杂的质因数分解或倍数分组的额外步骤。
效率:
- 通过记录有效值的下标以及跳过无关值,优化了因子遍历的时间复杂度。
- 路径压缩的并查集进一步加速了连通性检查和更新。
鲁棒性:
- 因为跳过了不在
nums中的倍数,该算法能有效避免冗余计算,适用于各种threshold和nums的大小组合。
- 因为跳过了不在
总结
该算法的核心是利用并查集来维护连通性,通过因子 g 遍历和倍数查找构建连通关系,同时通过路径压缩和上界优化减少冗余操作。代码简洁,逻辑清晰,是一种非常高效且易于实现的解决方案。
第427场周赛



